計算機非常擅長使用結構化數據,因此針對大量的數據和表格的處理,它都信手拈來。但是對於人類來說,我們是以非結構化的文字等信息進行交流的。計算機並不擅長處理這些非結構化數據,因此如何讓計算機理解人類的語言,一直以來是一大難題。
什麼是自然語言處理?與其他領域相比,針對金融領域的自然語言處理有何不同?
NLP本身是人工智能中的一個重要的方向,簡單來說,處理自然語言的過程就是讓機器去理解人的文本或語言,其中如翻譯、語音識別、語義理解、智能問答,知識圖譜等都屬於NLP的范疇。
自計算機誕生伊始,人類就致力於讓機器來理解我們語言。隨著人工智能、計算機科學、信息工程、統計學、甚至語言學等學科知識的不斷進步,目前NLP已經擁有了大量的商業應用,如機器翻譯(Google翻譯、有道翻譯等)、知識圖譜(以Google為代表的搜索引擎)、智能問答(Apple的Siri、亞馬遜的Alexa以及各種智能機器人)等等。
但是,金融領域的NLP目前仍處於探索階段,金融本身是一個專業性很高的領域,很多詞匯在金融語境下會產生特殊含義,所有的子問題都會有一個獨特的理解方式,而且金融領域衡量處理結果的方式也與其他領域不同。比如針對輿情分析,金融領域要求對市場未來的走勢有一定的預見性。
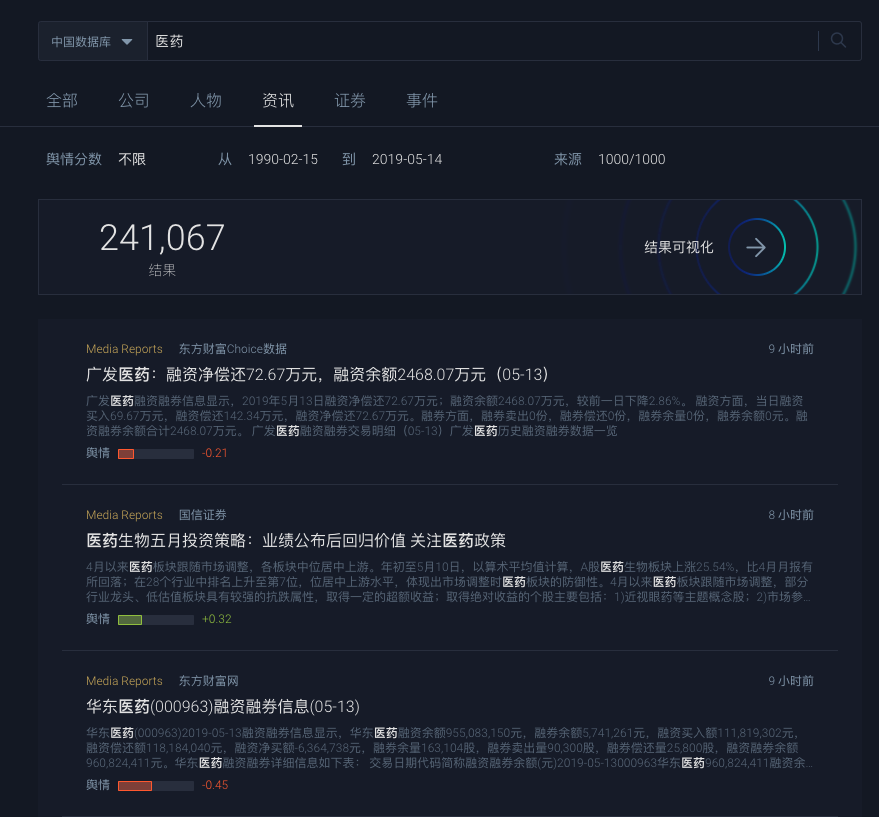
妙盈科技AMI系統中對新聞輿情進行分類與評分處理
因此,金融領域的NLP需要准備特殊的訓練數據集,而目前NLP所有方法都是基於大量的數據集基礎上,數據集的缺乏也是目前NLP在金融領域所面臨的最大問題之一,這也是金融領域高度的專業性與深度導致的。
在妙盈科技,我們應用NLP專注於解決NER、關系提取以及知識圖譜的建立。利用已經關聯好的其他數據對數據集進行補充,也就是利用知識圖譜來彌補訓練集的不足。

MioTech AMI - 知識圖譜
自然語言處理的發展經歷了哪些階段?遇到了哪些挑戰?
NLP的發展進程與人工智能發展的腳步大體相同,都經歷了如下的發展階段:
-
20世紀50 - 80 年代:簡單的實現人類掌握的規則,基於人類的經驗;
-
20世紀90年代 - 2000年左右:主要基於統計學的原理與方法;
-
2000年之後至今,由於數據的大幅增強、計算力的大幅提升,人們也逐漸開始將如日中天的深度學習方法引入到NLP領域中,在機器翻譯、問答系統、自動摘要等方向取得了重大突破。
但同時也應當注意到,NLP目前也仍然面臨諸多的挑戰。人類的語言非常簡練,在很多對話中是省略背景知識的。人類自己是可以很容易地理解這種省略的背景知識,但在NLP的過程中卻可能是很大的挑戰。
比如「司機,我在前門下車」這句話,當機器不了解具體語境的時候,就難以分清究竟在公交車前門,還是在北京前門站下車。
面向中文與英文的NLP存在哪些不同?中文NLP,特別是在金融領域存在哪些難點,有沒有某種算法是最佳的?
從語言本身上來看,英文比中文更直接,利用名詞就可以很大程度上判斷出一句話的語義。作為表音文字,英文還可以通過語法、時態、詞性、詞根、詞綴、單復數等形式來讓機器判斷真實意圖。
中文是象形文字,沒有各種詞性的轉換,也無法對某個單字進行拆分,因此機器一定要通過上下文語境來判斷具體語義。由於中文的特殊性,同一個任務、同一個模型在英文語境的表現一般要比中文好。
中文分詞是中文NLP的難點之一。如「結婚的和尚未結婚的」,應該分詞為「結婚/的/和/尚未/結婚/的」,還是「結婚/的/和尚/未/結婚/的」,不同的分詞方法會產生一定的歧義。再比如,「美國會通過對台售武法案」,我們既可以切分為「美國/會/通過對台售武法案」,又可以切分成「美/國會/通過對台售武法案」。
隨著深度學習的普遍使用,中文與英文在語言上的差異也逐漸變成訓練數據量上的差異,以往在NLP領域,可供使用的中文數據量比英文數據要少的多,這是目前中文NLP的難點之一。但是隨著有越來越多的人投入到中文人工智能以及NLP領域的研究中來,中文數據集不足的問題正在逐年改善。
在金融領域,針對基礎性問題,中英文所處的階段其實大體相同,但是針對如情感分析、市場預測等復雜問題,由於要結合具體的語境以及相應的應用場景,同時要考慮訓練的數量級問題,無論是中文還是英文的NLP要走的路都還有很多。
一個強大的NLP系統能夠幫助金融機構解決哪些實際問題?
全網輿情監控、產業鏈分析、讓機器幫助金融機構閱讀大量新聞。
例如,商業銀行希望使用更全面的數據進行企業的信貸風險管理,提前感知企業的潛在風險。目前常規的風險評估方法是根據企業公布的年報,並綜合信貸員實地調查的結果進行判斷,但是由於企業自身風險報出通常具有滯後性,公開信息覆蓋度不高,看到的往往只是冰山一角,因此判斷風險的手段十分單一。這也是NLP與人工智能可以發揮作用的地方。
NLP可以對信息進行多維關系的挖掘,評估企業之間的關系,並通過知識圖譜直觀呈現企業之間的關聯,提前設立預警信號,一旦企業關系網內的相關對象出現任意變動,便可根據關系權重,快速地評估對整個關系網的影響程度。

知識圖譜在企業信用風險預測中的作用
根據上市公司公開財報進行產業鏈挖掘是我們對NLP的又一應用。產業鏈數據以所有A股上市公司財報為原始數據源,根據公開財報中的主營業務構成,提取關鍵詞後輸入至預訓練的神經網絡中,對其進行向量表達。接下來,我們對輸入向量進行基於密度的聚類計算,輸出不同密度的集群,並最終進行集群命名。
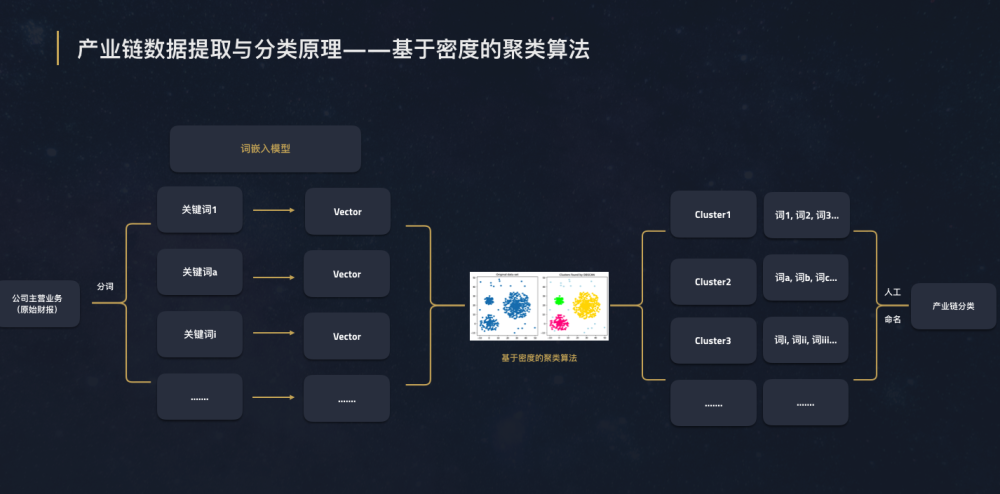
產業鏈數據提取原理——基於密度的聚類算法
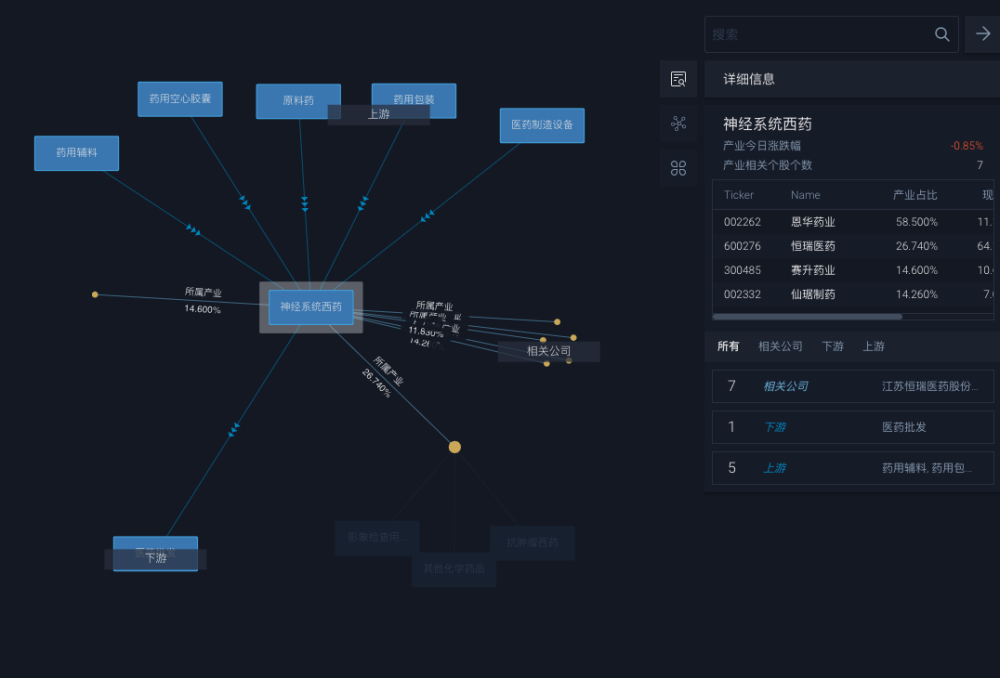
MioTech AMI 產業鏈數據展示
未來,中文NLP將會有哪些突破?
隨著每天產生的數據越來越多,可供機器進行訓練的數據集也會不斷增多。同時,隨著深度學習的發展,算法的不斷進步,將不斷降低對人類以往經驗的依賴度,就像Alpha Go,擺脫人類經驗後,它會表現更加出色。
特別是在BERT模型出現後,刷新了很多傳統NLP問題的准確程度,甚至在機器閱讀理解上,有些模型的准確程度已經全面超越人類。以機器閱讀理解為例,今年,人工智能在斯坦福大學閱讀理解測試(SQuAD)中擊敗了人類。根據SQuAD網站上的排行榜顯示,截至3月20日,使用的是BERT算法模型的EM得分(精確匹配,提供准確的問題答案)為87.147,排在首位,得分高於人類的86.831分。
從中文角度,NLP將向著深度學習的方向繼續發展,隨著數據集越來越豐富,針對復雜語義上的關系抽取將會更准確、針對情感識別也將逐漸進步。妙盈科技,作為這一賽道中面向金融領域的人工智能公司,隨著NLP算法的發展,我們的核心技術即實體識別與關系提取將會更加准確,提供的應用也將愈發成熟。